
Decode-Free Information Extraction: Evidence Selection in a Single Forward Pass
Evidence selection — deciding which passages are relevant to a query — sits at the heart of RAG pipelines, open-domain QA, and multi-hop reasoning. In this project I ask a simple question: can we get LLM-quality relevance judgments without paying the cost of autoregressive decoding?
The answer turns out to be yes. By classifying passages directly from the hidden states of a single LLM forward pass, we get rich cross-passage reasoning at essentially zero decoding cost — and beat strong in-domain baselines by a wide margin.
The code is on GitHub: Yuhengli77/Decode-Free-Information-Extraction.
The problem with existing approaches
Every common approach to evidence selection makes a painful trade-off:
| Method | Approach | Key limitation |
|---|---|---|
| Dual-Tower | Encode query and passages independently, rank by cosine similarity | No cross-attention; no inter-passage interaction |
| Cross-Encoder | Concatenate query with each passage, score independently | Rich query–passage interaction, but zero inter-passage interaction; 512-token windows can’t fit all passages |
| LLM Generation | Prompt an LLM to judge relevance via generated text | Powerful reasoning, but autoregressive decoding is slow — even a “yes/no” requires sequential token generation |
For multi-hop questions — where the relevance of one passage depends on information in another — independent scoring is theoretically insufficient. Yet the only approach that enables cross-passage reasoning (LLM generation) pays a heavy latency cost.
The key insight: modern LLMs have context windows (32K+ tokens) large enough to hold a query and all candidate passages in one sequence — far beyond what encoders allow. So instead of generating text, we read each passage’s relevance straight out of its hidden state. We get inter-passage interaction with no decoding at all.
Method
Given a query and N candidate passages, we pack everything into a single sequence:
Question: {query} Passage 1 Title: ... {text} [EOS] | Passage 2 ... [EOS] ... Passage N ... [EOS]
One forward pass produces hidden states at every position. For each passage, we grab
the hidden state at its [EOS] token and apply a binary classifier:
label_i = sigmoid(W · h_EOS_i + b) → 0 (irrelevant) or 1 (relevant)
I investigate two backbone variants.
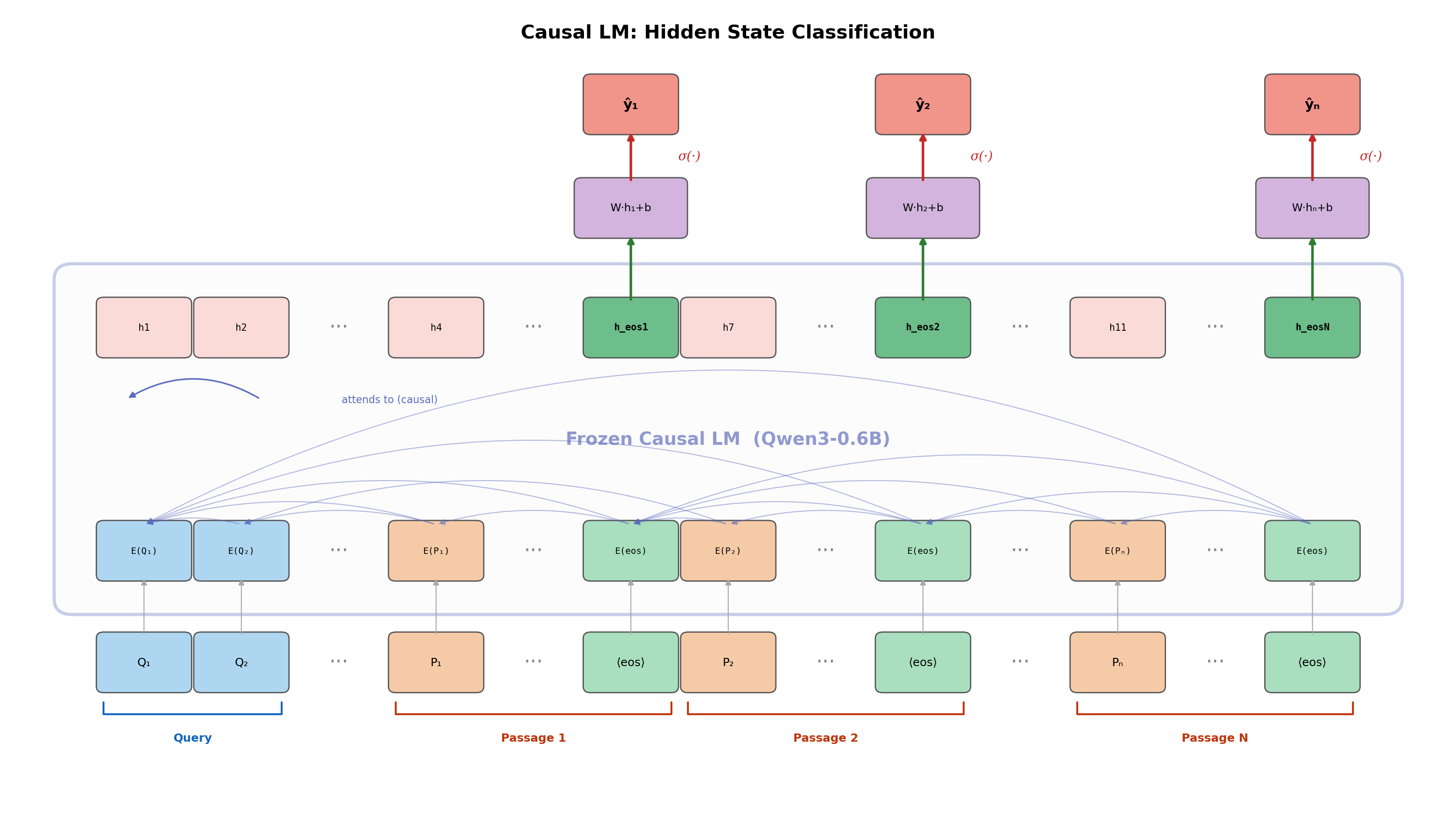
Causal LM (Qwen3-0.6B)
Each [EOS] token attends to the query and all preceding passages
(unidirectional inter-passage interaction), leveraging the general reasoning ability
that comes from next-token-prediction pretraining.
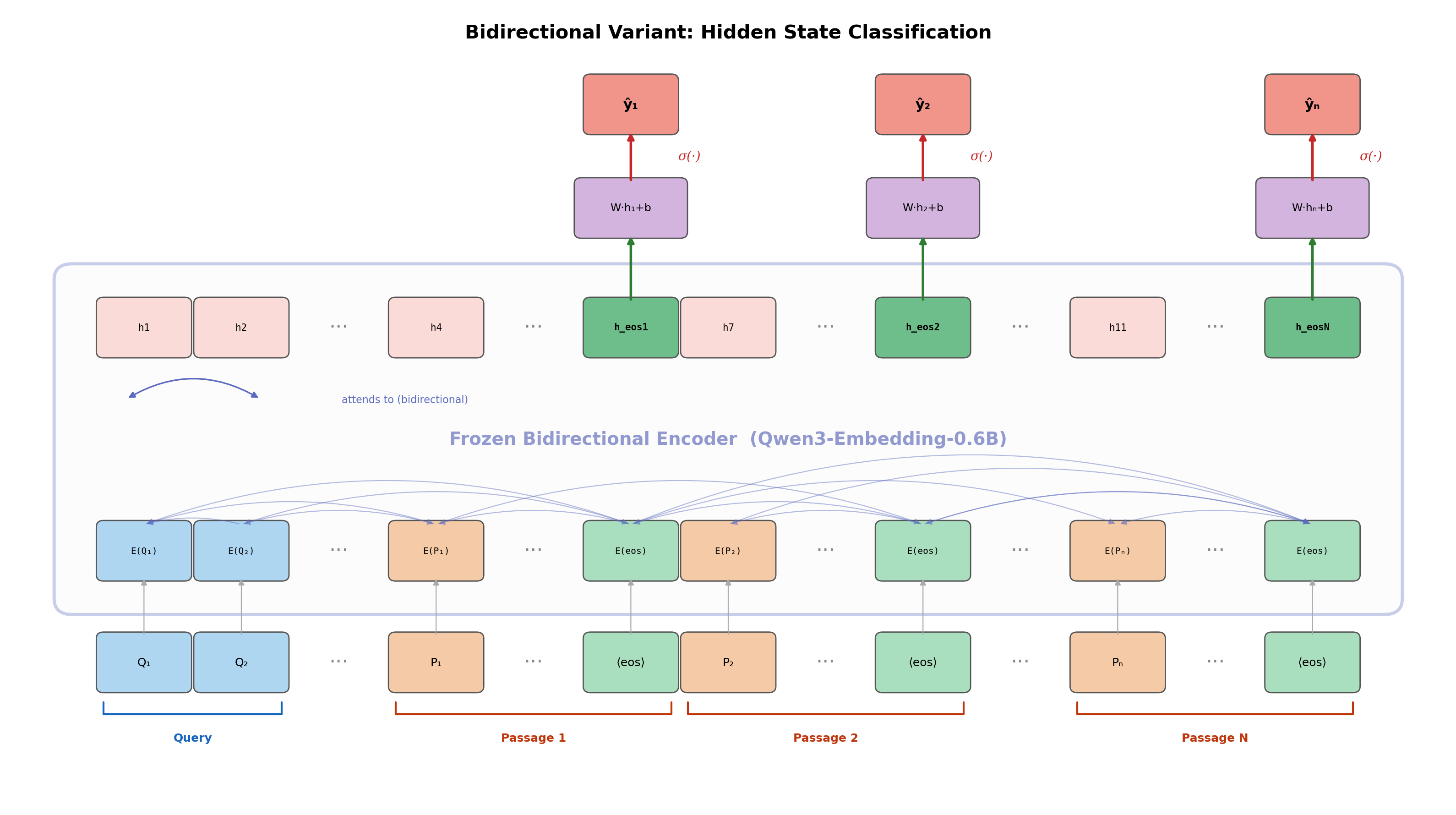
Bidirectional (Qwen3-Embedding-0.6B)
Each [EOS] token attends to all passages in both directions (full inter-passage
interaction), built on a contrastive-learning pretrained backbone.
Both are evaluated with a frozen backbone (only the linear head is trained) and with LoRA fine-tuning. Here’s how the design space lines up:
| Method | Query–Passage interaction | Inter-passage interaction | Decoding cost |
|---|---|---|---|
| Dual-Tower | None | None | None |
| Cross-Encoder | Full (bidirectional) | None | None |
| LLM Generation | Full (causal) | Unidirectional | O(T) tokens |
| Ours (Causal) | Full (causal) | Unidirectional | None |
| Ours (Bidirectional) | Full (bidirectional) | Full | None |
Experiments
Dataset: HotpotQA (distractor setting)
Each example pairs a multi-hop question with 10 paragraphs (2 gold + 8 distractors), with sentence-level supporting-fact annotations collapsed to paragraph-level binary labels. Multi-hop questions are the perfect testbed here: they require cross-paragraph reasoning, so they directly test whether inter-passage interaction actually helps.
Baselines
- Dual-Tower (all-MiniLM-L6-v2): cosine similarity, no interaction
- Cross-Encoder (ms-marco-MiniLM-L6-v2): query–passage interaction only
- ModernBERT Dual-Tower (ModernBERT-embedding-CMNBRL): HotpotQA-related embedding model
- HotpotQA Cross-Encoder (hotpotqa-mixer-2000): HotpotQA-specific reranker
Generic baselines are used off-the-shelf. Our models and the two in-domain baselines use HotpotQA supervision; frozen variants train only the linear head, while LoRA variants additionally adapt the backbone.
Results
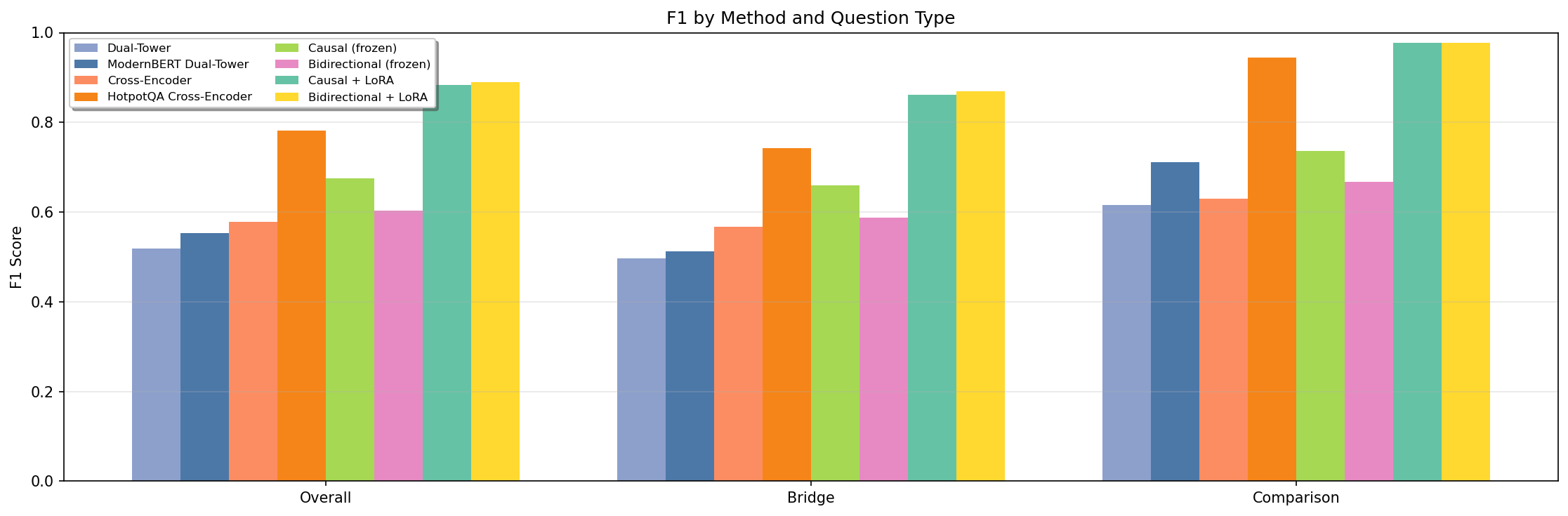
Paragraph-level F1 on 7,345 test examples:
| Method | Overall F1 | Bridge F1 | Comparison F1 |
|---|---|---|---|
| Dual-Tower | 0.519 | 0.496 | 0.616 |
| ModernBERT Dual-Tower | 0.553 | 0.512 | 0.712 |
| Cross-Encoder | 0.578 | 0.567 | 0.630 |
| HotpotQA Cross-Encoder | 0.782 | 0.742 | 0.944 |
| Causal LM (frozen) | 0.675 | 0.659 | 0.737 |
| Bidirectional (frozen) | 0.604 | 0.588 | 0.667 |
| Causal LM + LoRA | 0.884 | 0.861 | 0.977 |
| Bidirectional + LoRA | 0.890 | 0.869 | 0.977 |
What I learned
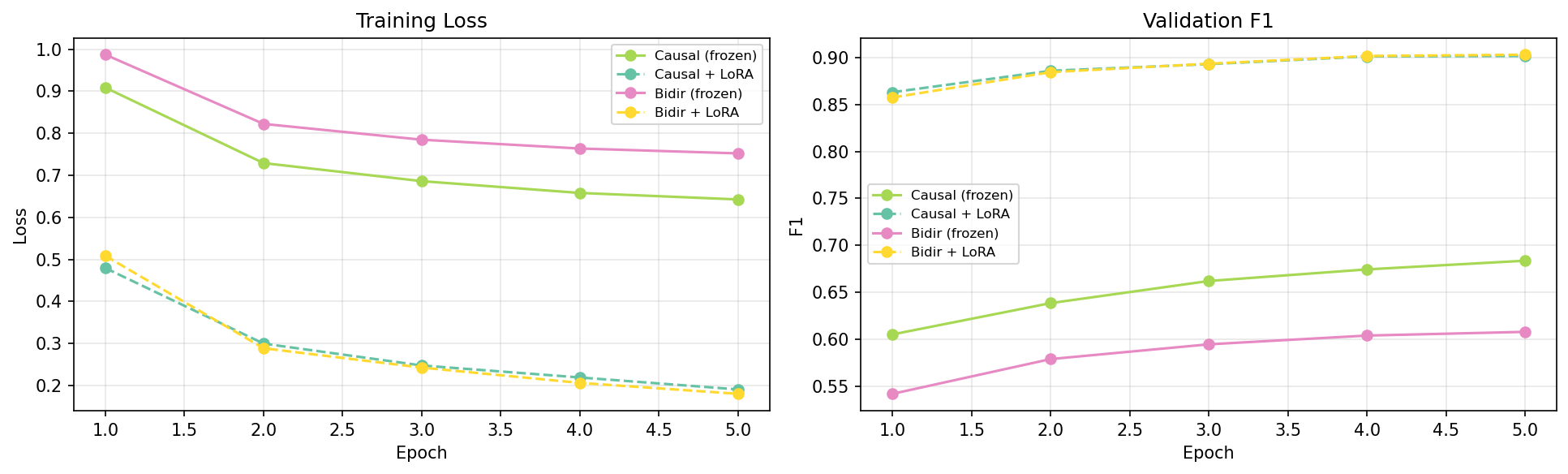
Frozen backbones already encode relevance signals. Even with no fine-tuning, the causal LM (0.675 F1) beats both generic baselines — dual-tower (0.519) and cross-encoder (0.578) — using only a linear head on frozen hidden states. Pretrained LLM representations apparently carry meaningful passage-relevance information that a simple classifier can pull out.
Causal attention beats bidirectional in the frozen setting. The frozen causal LM (0.675) outperforms the frozen bidirectional model (0.604), even though the latter has full inter-passage attention. I read this as the stronger general-purpose representations from next-token-prediction pretraining winning out over a contrastive-learning objective that was optimized for embedding similarity rather than discriminative classification.
LoRA closes the gap and tops the leaderboard. With LoRA, both backbones reach ~0.89 F1, beating the HotpotQA-specific cross-encoder (0.782) by a wide margin. The bidirectional model (0.890) edges out the causal variant (0.884), suggesting full inter-passage attention gives a small advantage once the backbone is adapted to the task.
Takeaway
You don’t need to decode to reason. By treating an LLM’s forward pass as a feature extractor over the whole query-plus-passages sequence, decode-free classification delivers inter-passage reasoning at a fraction of the cost of generation — and, after a light LoRA touch, outperforms purpose-built rerankers on multi-hop evidence selection.
Curious about the implementation? Everything is on GitHub.